Two items high on the list of concerns for many companies are backups, and cost. We recently had a client looking for a cost-effective but reliable solution for backing up their internal SharePoint 2010 environment.
So, without reinventing the wheel, we deployed a nice little PowerShell script produced by the good people over at CodePlex called SharePoint (2010) Farm Backup.
We modified the script to fit our client’s environment, and wrapped it in a batch file that does a few other clean-up and move-related tasks, scheduled it nightly, and were done, or so we thought.
Seemingly randomly, the client would call and be locked out of one of their SharePoint sites. The fix was easy enough – open Central Admin, navigate to Application Management / Site Collections, Configure Quotas and Locks:
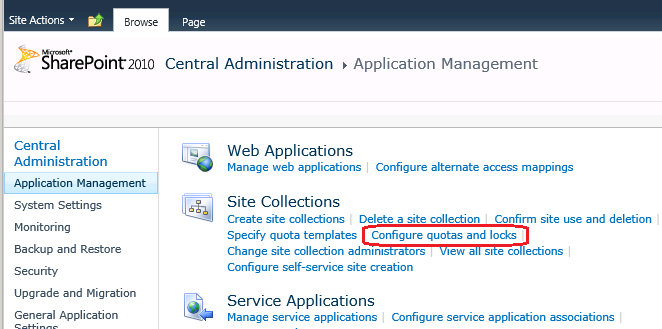
SharePoint 2010 Central Administration – Quotes and Locks
Select the site that is locked out, and change the status from “Read-only” to “Not Locked”.
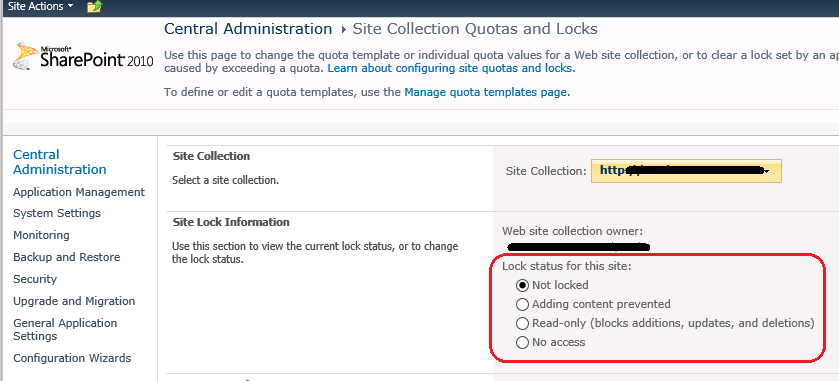
SharePoint 2010 Central Administration – Change Lock Status
Fine, but why is it happening?
The PowerShell script that is being used to back up the sites puts them into a Read-only status, to ensure no changes occur during the backup routine. On occasion though, PowerShell is crashing. It seems to happen at a random point during execution (meaning any of the sites “could” potentially be locked out, depending on how far the script got before it died.)
Each time the crash occurred, we would see a very generic Application Log entry on the server:
Log Name: Application
Source: Windows Error Reporting
Date: 2/23/2015 10:00:56 PM
Event ID: 1001
Task Category: None
Level: Information
Keywords: Classic
User: N/A
Computer: %servername%
Description:
Fault bucket , type 0
Event Name: APPCRASH
Response: Not available
Cab Id: 0
Problem signature:
P1: powershell.exe
P2: 6.1.7600.16385
P3: 4a5bc7f3
P4: ntdll.dll
P5: 6.1.7601.18247
P6: 521eaf24
P7: c00000fd
P8: 0000000000053520
P9:
P10:
Apparently we’re not the only ones seeing this problem, as it is also reported in the CodePlex discussion forums.
Knowing this is a little out of our power to actually fix, (there must be some set of circumstances that occurs during the execution of the script that will occasionally cause PowerShell to crash, and I highly doubt it is at the top of Microsoft’s list of things to fix) we needed to come up with a workaround that would allow the client to continue working, but that still gets regular usable backups.
What we want to happen moving forward is to:
- Notice that the error has occurred.
- Log what sites are in “Read-only” status.
- Unlock the sites.
- Notify the client that the crash occurred, and provide the current status of the sites.
Note: The notification is important in case the backup starts crashing on a more regular basis and backup frequency becomes an issue.
So we decided to add a little error trapping of our own.
We created 3 new scripts:
- A batch file to fire when event 1001 occurs in the Application log
- A PowerShell script to check the status of the SharePoint sites
- A PowerShell script to change the status of the SharePoint sites
The reason for the two separate PowerShell scripts is because I want to output the status of the sites to a log file before and after the change scripts run in the hopes that we’ll catch some pattern that will help us determine the cause of the initial crash.
Let’s look at the 2 PowerShell scripts first:
Powershell_Crash_LockState_Check.ps1
.sharepoint.ps1
Get-SPSite $SiteName | select ReadOnly,Readlocked,WriteLocked,LockIssue | ft –autosize
The “Check” script is simply accepting an argument (this will be the SharePoint site name), loading the SharePoint components for PowerShell, checking the status of the site and formatting it into a table.
Powershell_Crash_LockState_Change.ps1
.sharepoint.ps1
$site = Get-SPSite -Identity $SiteName
$site.readonly = $false
The “Change” script is similar. It accepts an argument (again the SharePoint site name), registers the SharePoint components for PowerShell, and changes the status of the site to “Not Locked”.
With those two scripts in place, we can now use a batch file to cycle through the sites, gather information, and unlock them:
Note: In this case our client has 4 sites on their server. We could make this script more generic by reading the sites and adding logic to dynamically cycle through them, but being that we only have one client with this issue right now, and we were pressed for time to get it in place, we stopped here. If you are going to use this script, you can simply add or remove sites and their references within the script. The yellow highlighted text would need to be changed for another environment.
Powershell_Crash_Alert.bat
echo .>C:localscriptLockState.txt
>C:localscriptLockState.txt (
echo An event on the company SharePoint Server indicates a possible crash during the SharePoint Backups that can leave the site[s] in a Read-Only state.
echo Checking and logging status of sites PRIOR to unlock routine…
echo.
)set CHECKSTATUSFLAG=FALSE:START_STATUS_CHECKset CURRENTSITE=http://SharePointSite#1
IF %CHECKSTATUSFLAG%==UNLOCK goto UNLOCK_SITE
goto BUILDHEADER:SharePointSite#2set CURRENTSITE=http://SharePointSite#2
IF %CHECKSTATUSFLAG%==UNLOCK goto UNLOCK_SITE
goto BUILDHEADER:SharePointSite#3set CURRENTSITE=http://SharePointSite#3
IF %CHECKSTATUSFLAG%==UNLOCK goto UNLOCK_SITE
goto BUILDHEADER:SharePointSite#4
set CURRENTSITE=http://SharePointSite#4
IF %CHECKSTATUSFLAG%==UNLOCK goto UNLOCK_SITE
goto BUILDHEADER
:BUILDHEADER
REM Setup Header
(
echo Site: ***%CURRENTSITE%***
)>>C:localscriptLockState.txt
goto CHECK_STATUS
:CHECK_STATUS
IF %CHECKSTATUSFLAG%==TRUE goto UNLOCK_SITE
@powershell -Command “& {C:localscriptPowershell_Crash_LockState_Check.ps1 %CURRENTSITE%}” >> C:localscriptLockState.txt
goto NEXTSITE
:UNLOCK_SITE
@powershell -Command “& {C:localscriptPowershell_Crash_LockState_Change.ps1 %CURRENTSITE%}”
:NEXTSITE
IF %CURRENTSITE%==http://SharePointSite#1 goto SharePointSite#2
IF %CURRENTSITE%==http://SharePointSite#2 goto SharePointSite#3
IF %CURRENTSITE%==http://SharePointSite#3 goto SharePointSite#4
IF %CURRENTSITE%==http://SharePointSite#4 goto CHECKFLAG
:CHECKFLAG
IF %CHECKSTATUSFLAG%==FALSE goto CHANGEFLAG_UNLOCK
IF %CHECKSTATUSFLAG%==UNLOCK goto RECHECK_STATUS
IF %CHECKSTATUSFLAG%==COMPLETE goto SENDALERT
:CHANGEFLAG_UNLOCK
set CHECKSTATUSFLAG=UNLOCK
goto START_STATUS_CHECK
:RECHECK_STATUS
set CHECKSTATUSFLAG=COMPLETE
(
echo.
echo Checking and logging status of sites AFTER unlocked routine.
echo If any of the sites below contain a READ-ONLY status then Manual Intervention is required on that/those site[s].
echo.
)>>C:localscriptLockState.txt
goto START_STATUS_CHECK
:SENDALERT
C:localbinblat -server mailserver -f alert@company.com -to user@company.com -subject “Company SQL Server Reporting Potential Backup Issue” -bodyF C:localscriptLockState.txt
:END
Note: In case you’re not familiar, Blat is a little SMTP program we often use that has been downloaded to this SharePoint server to send the email notification.
In a nutshell the above script loops through itself 3 times, completing the following:
- Documenting the current status of the SharePoint Sites.
- Unlocking the SharePoint Sites.
- Re-documenting the current status of the SharePoint sites.
That information is then emailed to a group of people that can review and take action if necessary.
The email that arrives for the notification looks like this (and is based on the “C:localscriptLockState.txt” file generated by the batch file):
From: alert@company.com [mailto:alert@company.com] Sent: Friday, March 13, 2015 10:55 AM
To: Casey Witham
Subject: Company SQL Server Reporting Potential Backup IssueAn event on the Company SharePoint Server indicates a possible crash during the SharePoint Backups that can leave the site[s] in a Read-Only state.
Checking and logging status of sites PRIOR to unlock routine…Site: ***http://SharePointSite#1***ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False FalseSite: ***http://SharePointSite#2***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Site: ***http://SharePointSite#3***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
True False False
Site: ***http://SharePointSite#4***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Checking and logging status of sites AFTER unlocked routine.
If any of the sites below contain a READ-ONLY status then Manual Intervention is required on that/those site[s].
Site: ***http://SharePointSite#1***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Site: ***http://SharePointSite#2***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Site: ***http://SharePointSite#3***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Site: ***http://SharePointSite#4***
ReadOnly ReadLocked WriteLocked LockIssue
——– ———- ———– ———
False False False
Finally, in order to get this script to function, a new Task in Task Scheduler is created:

Scheduled Task – PowerShell Crash Alert Properties
With the following trigger:
Begin the Task: On an event
Log: Application
Source: Windows Error Reporting
Event ID: 1001

PowerShell Crash Alert – Scheduled Task Trigger
With the following action:
Action: Start a Program
Program/Script: C:localscriptPowershell_Crash_Alert.bat
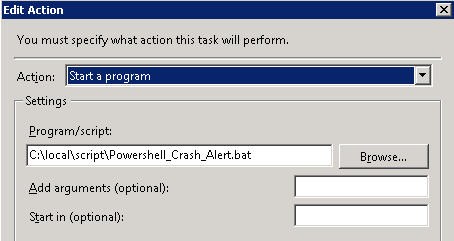
PowerShell Crash Alert – Scheduled Task Action
This script will now be executed if the Application Log reports event ID 1001 from Windows Error Reporting.
We may end up taking this script one step farther and have it re-invoke the backup script at the end of its routine. For now, the only reason we are not doing that is because we are still collecting information on frequency, and hoping to find the root cause. Automating another call to the backup routine could potentially put us into an endless loop situation (if the crash starts happening frequently).
Also, the Event ID we’re using to trigger the batch file can be logged for other application crashes, which could potentially start the backup at a time that would be inconvenient.
Although I do not consider this a permanent solution, it does give the client a way to continue operating without manual intervention when the crash does occur. We’re currently seeing the crash frequency about once every 4 to 6 weeks, and for our client this is a suitable workaround.
Hopefully this can assist others experiencing the same issue.